

Na een ecologische quickscans moet vaak onderzoek naar vleermuizen plaatsvinden. Op dit moment is dat een tijdrovende bezigheid en bovendien zeer kostbaar. Daarnaast zijn er te weinig ecologen beschikaar voor alle onderzoeken om aan de vraag te voldoen. Dit is niet zo vreemd: het is nachtwerk, wat niet iedereen prettig vindt.
Voor Aquila Ecologie is dit reden geweest om te beginnen met een AI-model om vleermuizen te identificeren. In samenwerking met de NDFF hebben we een AI-model gemaakt dat met 91% nauwkeurigheid vleermuis-individuen op soort kan determineren op basis van geluid. Deze geluiden moeten opgenomen zijn met speciale opname-apparatuur die hoge geluidsfrequenties kan opnemen. Daarna kan dit door het ontwikkelde AI model worden gedetermineerd. Maar hoe gaat het ontwikkelen van zo’n AI-model nou eigenlijk technisch in zijn werk?
Allereerst hebben we een grote dataset van vleermuisgeluiden nodig waarvan de determinatie met zekerheid vastgesteld is. Bij sommige vleermuissoorten is dit gemakkelijk, zo zijn er veel opnamen van Gewone dwergvleermuis. Er zijn echter ook soorten die geluiden maken die lastig van andere soorten te onderscheiden zijn. Deze geluiden zijn vaak opgenomen vóórdat of nadat dieren gevangen zijn en op uiterlijk gedetermineerd zijn. Hiervan zijn veel minder geluiden beschikbaar.
Machine learning heeft eigenlijk een zo groot mogelijke variatie aan geluiden nodig. Zo leert de computer om te onderscheiden wat er precies typisch is aan de roep van een bepaalde vleermuissoort, en wat er toevallig een variatie of een achtergrondgeluidje is. Om de hoeveelheid data kunstmatig te vergroten gebruiken we een trucje, dat in jargon data-augmentatie heet. Hierbij mixen we de geluiden waar de AI op getraind wordt met verschillende achtergrondgeluiden om toch variatie toe te voegen. Deze achtergrondgeluiden moesten we eerst verzamelen, omdat ze wel in hoge frequentie opgenomen moeten worden.
Vervolgens worden alle gegevens herhaaldelijk door een algoritme ‘bekeken’. Dit algoritme past zichzelf steeds een klein beetje aan op basis van de gegevens. Het zoekt op een complexe manier patronen in de data. Elke keer dat het algoritme de data ‘bekijkt’, wordt het een stukje beter in het herkennen van vleermuizen. De software van Aquila Ecologie geeft dit aan tijdens het trainen van het model:
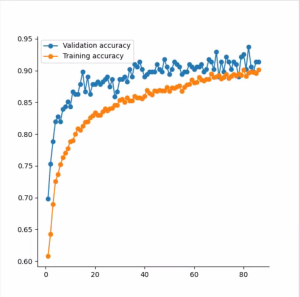
De volgende stap is om deze techniek bruikbaar te maken voor het analyseren van grote datasets van bijvoorbeeld meerdere weken. Hiervoor moet de software niet alleen vleermuissoorten kunnen onderscheiden, maar ook weten wanneer er geen vleermuis op de opname staat. Dit doen we door heel veel omgevingsgeluid op te nemen en de software te leren die onderscheiden.